More about MLSS 2010 could be found http://mlss10.rsise.anu.edu.au/proceedings

Tuesday, December 28, 2010
Thursday, December 23, 2010
[ASR] Still Tandem systems

Download now or preview on posterous
combining phonetic attributes using conditional random field.pdf (112 KB) The attached paper models phonetic attributes with CRF models. However, the sentence interests me most is the following one:
As described in [1] we used the linear output of the MLPs with a KL transform applied to them to decorrelate the features, as this gave the best results for the HMM system.
[1] H. Hermansky, D. Ellis, and S. Sharma, "Tandem connectionist feature stream extraction for conventional HMM systems", in Proc. of the ICASSP 2000.
Maybe sometime we could also try to refine the posterior features from NN for HMM systems.
Monday, December 20, 2010
[Linux] Mac configure type
In many cases the build step involves running a configure script. Occasionally you'll run a configure script that gives error message stating that the host type cannot be determined. In such a case, you can usually either specify the configure option --host=powerpc-apple-darwin6.4 as I've done in the examples below. (Note in this case, we are using darwin6.4. To determine the correct release of darwin, enter the command uname -r.) You can alternatively copy two files into the build directory, that is, into the same directory that contains the script configure.
Occasionally, the configure option --build=powerpc-apple-darwin6.4 is needed to produce the desired result (again assuming we're using darwin release 6.4). In some cases, there are additional steps to be performed. ...
Code:
cp /usr/share/libtool/config.guess . cp /usr/share/libtool/config.sub .
Sunday, December 19, 2010
Thursday, December 16, 2010
[Basic] Whitening
From: http://cis.legacy.ics.tkk.fi/aapo/papers/IJCNN99_tutorialweb/node26.html
Another useful preprocessing strategy in ICA is to first whiten the observed variables. This means that before the application of the ICA algorithm (and after centering), we transform the observed vector ![]() linearly so that we obtain a new vector
linearly so that we obtain a new vector ![]() which is white, i.e. its components are uncorrelated and their variances equal unity. In other words, the covariance matrix of
which is white, i.e. its components are uncorrelated and their variances equal unity. In other words, the covariance matrix of ![]() equals the identity matrix:
equals the identity matrix:
| (30) |
The whitening transformation is always possible. One popular method for whitening is to use the eigen-value decomposition (EVD) of the covariance matrix![]() , where
, where ![]() is the orthogonal matrix of eigenvectors of
is the orthogonal matrix of eigenvectors of ![]() and
and ![]() is the diagonal matrix of its eigenvalues,
is the diagonal matrix of its eigenvalues, ![]() . Note that
. Note that ![]() can be estimated in a standard way from the available sample
can be estimated in a standard way from the available sample ![]() . Whitening can now be done by
. Whitening can now be done by
where the matrix
Whitening transforms the mixing matrix into a new one, ![]() . We have from (4) and (34):
. We have from (4) and (34):
| (32) |
The utility of whitening resides in the fact that the new mixing matrix
| (33) |
Here we see that whitening reduces the number of parameters to be estimated. Instead of having to estimate the n2 parameters that are the elements of the original matrix
It may also be quite useful to reduce the dimension of the data at the same time as we do the whitening. Then we look at the eigenvalues dj of ![]() and discard those that are too small, as is often done in the statistical technique of principal component analysis. This has often the effect of reducing noise. Moreover, dimension reduction prevents overlearning, which can sometimes be observed in ICA [26].
and discard those that are too small, as is often done in the statistical technique of principal component analysis. This has often the effect of reducing noise. Moreover, dimension reduction prevents overlearning, which can sometimes be observed in ICA [26].
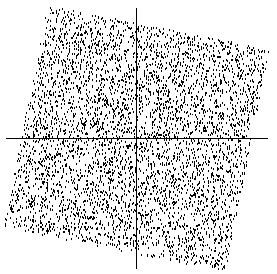
A graphical illustration of the effect of whitening can be seen in Figure 10, in which the data in Figure 6 has been whitened. The square defining the distribution is now clearly a rotated version of the original square in Figure 5. All that is left is the estimation of a single angle that gives the rotation.
In the rest of this tutorial, we assume that the data has been preprocessed by centering and whitening. For simplicity of notation, we denote the preprocessed data just by ![]() , and the transformed mixing matrix by
, and the transformed mixing matrix by ![]() , omitting the tildes.
, omitting the tildes.
Monday, December 13, 2010
[Basic] Cross-Entropy Criterion
Cross-Entropy Criterion is actually the Kullback Leibler Divergence.
KL divergence is a non-symmetric measure of the difference between two probability distributions P and Q. KL measures the expected number of extra bits required to code samples from P when using a code based on Q, rather than using a code based on P. Thus, P is the true distribution and Q is the estimated distribution. Typically P represent the "true" distribution of data, observations, or a precise calculated theoretical distribution. The measure Q typically represent a theory, model, description, or approximation of P.
Although it is often intuited as a distance metric, the KL divergence is not a true metric - for example, it's not symmetric: the KL from P to Q is not necessarily the same as the KL from Q to P.
For probability distributions P and Q of a discrete random variable their KL divergence is defined to be:
D_KL(P||Q)=\sum{ P(i) log[ P(i)/Q(i) ] }
In words, it is the average of the logarithmic difference between the probabilities P and Q, where the average is taken using the probabilities P. The KL divergence is only defined if P and Q both sum to 1 and if Q(i) > 0 for any i such that P(i) > 0. If the quantity 0 log 0 appears in the formula, it is interpreted as zero.
The attached document is the explanation for KL divergence from wikipedia.
Friday, December 10, 2010
Printing in NUS SoC
Printing in the School of Computing
Printing in SoC has long been a nightmare for users of "unsupported systems" like us. Fortunately, the most difficult part is actually *figuring out* how to get printing working on Linux, and since we already have, the steps you need to take to enable printing on your Linuxbox is relatively simple, especially if you're using a fairly recent and popular distro.
Here are detailed steps for recent versions of Ubuntu and OpenSUSE. They should be fairly similar in comparable distros.
Printing in Ubuntu
Since around the time of Hardy, everything you need to print to the SoC printers is available out-the-box on an Ubuntu system. To start printing, you simply need to configure a printer as follows:
Step 1
Make sure you are either connected to PEAP or to SoCVPN.
Go to System > Administration > Printing, key in your password, and hit the "New" button on the window that appears.
Step 2
Select Network Printer > Windows Printer via Samba on the left-hand column.
On the right, enter the following in the textfield under "SMB Printer"
nusstu/nts27.comp.nus.edu.sg/psts-dx
You can replace 'psts-dx' above with the name of whatever target printer you desire to add.
Check "Set authentication details now" and key in your NUSNET credentials.

You can hit "verify" to see if your connection is successful. Hit "Forward" when you're done.
Step 3
Select the printer manufacturer here. For the COM1 printers, pick "Lexmark". Then hit "Forward".

Step 4
Select the printer model here. For the COM1 printers, pick "T642".

Step 5
Optionally Key in some meta information for your new printer.

Hit "Apply" and you're done!!
Print a test page to boost your ego.
Printing in Kubuntu
IdyllicTux has a Video Tutorial on printing on Kubuntu. Steps are highly similar to those for Ubuntu.
Printing in OpenSUSE
This is based on the KDE version. Steps for OpenSUSE Gnome should be similar.
Step 1
Make sure you are either connected to PEAP or to SoCVPN.
Bring up the Yast Administrator Settings Panel (Application > System > Administrator Settings) and select "Printer"
In the window that opens, make sure "Printer configurations" is selected on the left-hand panel, then click "Add" near the bottom-center.
Step 2
Click "Connection Wizard" at the top-right.
In the page that results, Select "Print via Server Machine > Microsoft Windows/SAMBA (SMB/CIFS)" on the left-hand panel.
On the right, key in
- "nts27.comp.nus.edu.sg" for Server (NetBIOS Host Name)
- Your target printer name for Printer (Share Name), eg. psts-dx
- "nusstu" for Workgroup (Domain Name)
- Your NUSNET credentials under "Authenticate As"
- The printer manufacturer - "Lexmark" for the COM1 printers on the last drop-down.

Test the connection if you like. Hit "ok" when you're done.
Step 3
Under "Assign Driver", look for and select the driver for the target printer. For the COM1 printers, select the entry beginning with "Lexmark T642".
If you cannot find this in the list, you may need to install a driver package. Click "Add Driver" to do so. The following page should appear:

Check off the driver packages you would like to install. "cups-drivers" should contain the T642 driver for the COM1 printers, so check it if you haven't. Hit "ok" to install the driver packages.
You will be returned to the original page once you're done, and you should now find your driver in the list. Select it and hit "ok".

You're done!! Print a test page to boost your ego.
A word on changing password
The Yast printer configuration tool is a little unwieldy, and shockingly does not appear to have a direct way of changing your authentication password. When you change your NUSNET password, simply delete your existing printing configurations and re-add them following the steps above.
Monday, December 6, 2010
[Ogre] SDK Install
After dragging the SDK folder to local disk, before open the xcode project, be sure to run following command to make the xcode project adjusted to the current environment.
cmake -GXcode .
Saturday, December 4, 2010
3D Little Human Figures Clipart Big Collection

3D Little Human Figures Clipart – Big Collection
115 jpg | Up to 9001*6000 pix | 300 dpi | 282 Mb rar
Download:
Part 1 http://depositfiles.com/en/files/a9wxaatgz
Part 2 http://depositfiles.com/en/files/7f2ftolkj
Part 3 http://depositfiles.com/en/files/bozjkzeza
From: http://lordofdesign.com/3d-little-human-figures-clipart-big-collection/
Wednesday, December 1, 2010
[Latex] LaTex: Fixing Wrong Figure Numbers
From: http://www.terminally-incoherent.com/blog/2007/04/14/latex-fixing-wrong-figure-numbers/
ONE SENTENCE: PUT THE LABEL COMMAND AFTER CAPTION COMMAND FOR FIGURES.
What I tell you right now may save you hours of extensive debugging, cursing under your breath, commenting out custom code dealing with figure layout and much frustration. Whenever you use figures, always (and I mean ALWAYS EVER FOREVER ALWAYS) put \caption first, and \labelsecond like this:
\begin{figure}[htp] \centering \includegraphics{image.eps} \caption{Some Image} \label{fig:some-image} \end{figure}If you put the \label above \caption you will run into trouble when referencing figures inside subsections. In my case, the caption underneath the figure would say Fig. 4.2 but the output of \ref would be 4.3.10 because somehow it was picking up the section numbers wrong. The whole damn chapter 4 had the caption/label pairs flipped – but the rest of the document was fine. I have no clue what possessed me to write it this way.
Tuesday, November 30, 2010
[Feature] SIFT
In spite of significant progress in automatic speech recognition over the years, robustness still appears to be a stumbling block. Current commercial products are quite sensitive to changes in recording device, to acoustic clutter in the form of additional speech signals, and so on. The goal of replicating human performance in a machine remains far from sight.
Scale Invariant Feature Transform (SIFT) is an approach for detecting and extracting local feature descriptors that are reasonably invariant to changes in illumination, image noise, rotation, scaling, and small changes in viewpoint.
Detection stages for SIFT features:
1) Scale-space extrema detection
Interest points for SIFT features correspond to local extrema of difference-of-Gaussian filters at different scales.
Interest points (called keypoints in the SIFT framework) are identified as local maxima or minma of the DoG (difference of Gaussian) images across scales. Each pixel in the DoG images is compared to its 8 neighbors at the same scale, plus the 9 corresponding neighbors at neighboring scales. If the pixel is a local maximum or minimum, it is selected as a candidate keypoint.
For each candidate keypoint:
- Interpolation of nearby data is used to accurately determine its position;
- Keypoints with low contrast are removed;
- Responses along edges are eliminated;
- The keypoint is assigned an orientation.
To determine the keypoint orientation, a gradient orientation histogram is computed in the neighborhood of the keypoint (using the Gaussian image at the closest scale to the keypoint's scale). The contribution of each neighboring pixel is weighted by the gradient magnitude and a Gaussian window with a theta that is 1.5 times the scale of the keypoint.
Peaks in the histogram correspond to dominant orientations. A separate keypoint is created for the direction corresponding to the histogram maximum, and any other direction within 80% of the maximum value.
All the properties of the keypoint are measured relative to the keypoint orientation, this provides invariance to rotation.
2) Key point localization
3) Orientation assignment
4) Generation of keypoint descriptors
[Feature] Speech Recognition with localized time-frequency pattern detectors
Characteristics of the localized time-frequency features:

1) Local in frequency domain, not like MFCC, each feature is affected by all the frequencies;
2) Temporal dynamics, modeling long and variable time durations, while in MFCC, the features are all short time and fixed duration.
In this paper, the set of filters adopted is very simple, and are essentially basic edge detectors taking only values +1 and -1. The selection includes vertical edges (of varying frequency span and temporal duration) for onsets and offsets; wide horizontal edges for frication cutoffs; and horizontal edges tilted at various slopes to model formant transitions. The choices for the ranges of the various parameters were made based on acoustic phonetic knowledge, such as typical formant bandwidths, average phone durations, typical rates of formant movement, etc.[Book: Acoustic Phonetics]

With these filters, the features are computed as follows:
For each filter,
1) centering it at a particular frequency, and convolving with the whole spectrogram along the time axis for that specific frequency;
2) for each frequency value, we could get a time series of the convolution sums;
3) to reduce the dimension of features, the convolution sums are down sampled over a 16*32 point grid.
4) The 32 frequency points are taken linearly between 0 and 4kHz.
5) The 16 time points (which is specific to their task) is the centers of the 16 states (for the HMM word model) in the state alignment.
Thus, a feature refers to both the filter shape, and the time-frequency point (16*32 point grid).
In this paper, the task is to classify isolated digits. Each spectrogram is one single digit. The feature computed is per digit, thus is global to the target class.
###################
The problem with current frame based features is its non-localization, make it difficult to modeling speaker variabilities.
As shown in following figure:

Monday, November 29, 2010
[Speech] Phonetic cues
Download now or preview on posterous
Glass, Schutte_2009_Parts-based models and local features for automatic speech recognition.pdf (2115 KB) While automatic speech recognition systems have steadily improved and are now in widespread use, their accuracy continues to lag behind human performance, particularly in adverse conditions.
There has been much progress and ASR technology is now in widespread use; however, there is still a considerable gap between human and machine performance, particularly in adverse conditions.
How human evolution makes humans different from machines in perceiving speech signals?
What's the major differences between humans and machine when processing speech signals? And which are the crucial ones?
The parts-based model (PBM), based on previous work in machine vision, uses graphical models to represent speech with a deformable template of spectro-temporally localized "parts", as opposed to modeling speech as a sequence of fixed spectral profiles.
Perhaps most importantly, ASR systems have benefited greatly from general improvements in computer technology. The availability of very large datasets and the ability to utilize them for training models has been very beneficial. Also, with ever increasing computing power, more powerful search techniques can be utilized during recognition.
Reaching the ultimate goal of ASR - human-level (or beyond) performance in all conditions and on all tasks - will require investigating other regions of this landscape, even if doing so results in back-tracking in progress in the short-term.
Utilize the knowledge of acoustic phonetics and human speech perception in speech recognition.
We will argue that well known phonetic cues crucial to human speech perception are not modeled effectively in standard ASR systems, and that there is a benefit to model such cues explicitly, rather than implicitly.
The "glimpsing" model of speech perception suggests that humans can robustly decode noise-corrupted speech by taking advantage of local T-F regions having high SNR, and is supported by empirical evidence and computational models.
Auditory Neuroscience, Tonotopic maps. Also, recent research seeking to characterize the behavior of individual neurons in the mammalian auditory cortex has resulted in models in which cortical neurons act as localized spectro-temporal pattern detectors. ( represented by their so-called spectro-temporal receptive filed, or STRF).
+ Localized T-F pattern detectors
+ Explicit modeling of phonetic cues
Corpora:
acoustic ----------> phonetic cues ------------------> phonemes
Thursday, November 25, 2010
[Speech] Spectrogram
From: http://www-3.unipv.it/cibra/edu_spectrogram_uk.html
To analyze sounds it is required to have an acoustic receiver (a microphone, an hydrophone or a vibration transducer) and an analyzer suitable for the frequencies of the signals we want to measure. Eventually, a recorder may allow to permanently store the sounds to allow later analyses or playbacks.
A spectrograph transforms sounds into images to make "visible", and thus measurable and comparable, sound features the human hear can't perceive. Spectrograms (also called sonograms or sonagrams) may show infrasounds, like those emitted by some large whales or by elephants, as well as ultrasounds, like those emitted by echolocating dolphins and by echolocating bats, but also emitted by insects and small rodents.
Spectrograms may reveal features, like fast frequency or amplitude modulations we can't hear even if they lie within our hearing frequency limits (30 Hz - 16 kHz). Spectrograms are widely used to show the features of animal voices, of the human voice and also of machinery noise.
A real-time spectrograph displays continuously the results of the analyses on the incoming sounds with a very small - often not perceivable - delay. This kind of instrumentation is very useful in field research because it allows to continuously monitor the sounds received by the sensors, to immediately evaluate their features, and to classify the received signals. A spectrograph can be dedicated instrument or a normal computer equipped with suitable hardware for receiving and digitizing sounds and a software to analyze sounds and convert them into a graphical representation.
Normally, a spectrogram represents the time on the x axis, frequency on the y axis and the amplitude of the signals by using a scale of grays or a scale of colours. In some applications, in particular those related with military uses, the x and y axes are swapped.
The quality and features of a spectrogram are controlled by a set of parameters. A default set can be used for generic display, but some parameters can be changed to optimize the display of specific features of the signals.
Also, by modifying the colour scale it is possible to optimize the display of the amplitude range of interest.
Tuesday, November 23, 2010
[News] ACMTech Nov.23
AT&T Ups the Ante in Speech Recognition
CNet (11/18/10) Marguerite ReardonAT&T says it has devised technologies to boost the accuracy of speech and language recognition technology as well as broaden voice activation to other modes of communication. AT&T's Watson technology platform is a cloud-based system of services that identifies words as well as interprets meaning and contexts to make results more accurate. AT&T recently demonstrated various technologies such as the iRemote, an application that transforms smartphones into voice-activated TV remotes that let users speak natural sentences asking to search for specific programs, actors, or genres. Most voice-activated remotes respond to prerecorded commands, but the iRemote not only recognizes words, but also employs other language precepts such as syntax and semantics to interpret and comprehend the request's meaning. AT&T also is working on voice technology that mimics natural voices through its AT&T Natural Voices technology, which builds on text-to-speech technology to enable any message to be spoken in various languages, including English, French, Italian, German, or Spanish when text is processed via the AT&T cloud-based service. The technology accesses a database of recorded sounds that, when combined by algorithms, generate spoken phrases.
http://news.cnet.com/8301-30686_3-20023189-266.html
CNet (11/18/10) Marguerite ReardonAT&T says it has devised technologies to boost the accuracy of speech and language recognition technology as well as broaden voice activation to other modes of communication. AT&T's Watson technology platform is a cloud-based system of services that identifies words as well as interprets meaning and contexts to make results more accurate. AT&T recently demonstrated various technologies such as the iRemote, an application that transforms smartphones into voice-activated TV remotes that let users speak natural sentences asking to search for specific programs, actors, or genres. Most voice-activated remotes respond to prerecorded commands, but the iRemote not only recognizes words, but also employs other language precepts such as syntax and semantics to interpret and comprehend the request's meaning. AT&T also is working on voice technology that mimics natural voices through its AT&T Natural Voices technology, which builds on text-to-speech technology to enable any message to be spoken in various languages, including English, French, Italian, German, or Spanish when text is processed via the AT&T cloud-based service. The technology accesses a database of recorded sounds that, when combined by algorithms, generate spoken phrases.
http://news.cnet.com/8301-30686_3-20023189-266.html
What If We Used Poetry to Teach Computers to Speak Better?
McGill University (11/17/10)McGill University linguistics researcher Michael Wagner is studying how English and French speakers use acoustic cues to stress new information over old information. Finding evidence of a systematic difference in how the two languages use these cues could aid computer programmers in their effort to produce more realistic-sounding speech. Wagner is working with Harvard University's Katherine McCurdy to gain a better understanding of how people decide where to put emphasis. They recently published research that examined the use of identical rhymes in poetry in each language. The study found that even when repeated words differ in meaning and sound the same, the repeated information should be acoustically reduced as otherwise it will sound odd. "Voice synthesis has become quite impressive in terms of the pronunciation of individual words," Wagner says. "But when a computer 'speaks,' whole sentences still sound artificial because of the complicated way we put emphasis on parts of them, depending on context and what we want to get across." Wagner is now working on a model that better predicts where emphasis should fall in a sentence given the context of discourse.
http://www.eurekalert.org/pub_releases/2010-11/mu-wiw111710.php
McGill University (11/17/10)McGill University linguistics researcher Michael Wagner is studying how English and French speakers use acoustic cues to stress new information over old information. Finding evidence of a systematic difference in how the two languages use these cues could aid computer programmers in their effort to produce more realistic-sounding speech. Wagner is working with Harvard University's Katherine McCurdy to gain a better understanding of how people decide where to put emphasis. They recently published research that examined the use of identical rhymes in poetry in each language. The study found that even when repeated words differ in meaning and sound the same, the repeated information should be acoustically reduced as otherwise it will sound odd. "Voice synthesis has become quite impressive in terms of the pronunciation of individual words," Wagner says. "But when a computer 'speaks,' whole sentences still sound artificial because of the complicated way we put emphasis on parts of them, depending on context and what we want to get across." Wagner is now working on a model that better predicts where emphasis should fall in a sentence given the context of discourse.
http://www.eurekalert.org/pub_releases/2010-11/mu-wiw111710.php
Monday, November 22, 2010
Enabling Terminal's directory and file color highlighting in Mac
From: http://www.geekology.co.za/blog/2009/04/enabling-bash-terminal-directory-file-color-highlighting-mac-os-x/
By default Mac OS X’s Terminal application uses the Bash shell (Bourne Again SHell) but doesn’t havedirectory and file color highlighting enabled to indicate resource types and permissions settings.

Enabling directory and file color highlighting requires that you open (or create) ~/.bash_profile in your favourite text editor, add these contents:
export CLICOLOR=1 export LSCOLORS=ExFxCxDxBxegedabagacad
… save the file and open a new Terminal window (shell session). Any variant of the “ls” command:
ls ls -l ls -la ls -lah
… will then display its output in color.
More details on the LSCOLORS variable can be found by looking at the man page for “ls“:
man ls
LSCOLORS needs 11 sets of letters indicating foreground and background colors:
- directory
- symbolic link
- socket
- pipe
- executable
- block special
- character special
- executable with setuid bit set
- executable with setgid bit set
- directory writable to others, with sticky bit
- directory writable to others, without sticky bit
The possible letters to use are:
a black b red c green d brown e blue f magenta c cyan h light grey A block black, usually shows up as dark grey B bold red C bold green D bold brown, usually shows up as yellow E bold blue F bold magenta G bold cyan H bold light grey; looks like bright white x default foreground or background
By referencing these values, the strongstrongstrongstrongstrong
[Apple] Old versions of Xcode
There are a bunch of tools for Mac development on the site http://connect.apple.com
It also provides old versions of Xcode.
Old versions of iPhone SDK
From: http://iphonesdkdev.blogspot.com/2010/04/old-versions-of-iphone-sdk.html
You need Apple developer account to login
But Apple has disabled some of the links recentlyiPhone SDK 2.2.1 Leopard (10.5.4)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_for_iphone_os_2.2.1__9m2621a__final/iphone_sdk_for_iphone_os_2.2.19m2621afinal.dmg iPhone SDK 3.0 (Xcode 3.1.3) Leopard (10.5.7)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.0__final/iphone_sdk_3.0__leopard__9m2736__final.dmg
iPhone SDK 3.0 (Xcode 3.2) Snow Leopard (10.6.0)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.0__final/iphone_sdk_3.0__snow_leopard__final.dmg iPhone SDK 3.1 with Xcode 3.1.4 Leopard (10.5.7)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1__final/iphone_sdk_3.1_with_xcode_3.1_final__leopard__9m2809.dmg iPhone SDK 3.1 with XCode 3.2.1 for Snow Leopard (10.6.0)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1__final/iphone_sdk_3.1_with_xcode_3.2_final__snow_leopard__10a432.dmg iPhone SDK 3.1.2 with XCode 3.1.4 for Leopard (10.5.7)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1.2__final/iphone_sdk_3.1.2_with_xcode_3.1.4__leopard__9m2809.dmg iPhone SDK 3.1.2 with XCode 3.2.1 for Snow Leopard (10.6.0)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1.2__final/iphone_sdk_3.1.2_with_xcode_3.2.1__snow_leopard__10m2003.dmg
Update : You are too late, Apple has removed the links above.iPhone SDK 3.1.3 with XCode 3.1.4 for Leopard (10.5.7)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_3.1.3__final/iphone_sdk_3.1.3_with_xcode_3.1.4__leopard__9m2809a.dmg iPhone SDK 3.1.3 with XCode 3.2.1 for Snow Leopard (10.6.0)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_3.1.3__final/iphone_sdk_3.1.3_with_xcode_3.2.1__snow_leopard__10m2003a.dmg iPhone SDK 3.2 Final with Xcode 3.2.2 for Snow Leopard (10.6.0)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_3.2__final/xcode_3.2.2_and_iphone_sdk_3.2_final.dmg Xcode 3.2.3 and iPhone SDK 4 GM seed for Snow Leopard (10.6.2)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_4_gm_seed/xcode_3.2.3_and_iphone_sdk_4_gm_seed.dmg Xcode 3.2.3 and iPhone SDK 4 Final for Snow Leopard (10.6.2)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_4__final/xcode_3.2.3_and_iphone_sdk_4__final.dmg Xcode 3.2.3 and iOS SDK 4.0.1 for Snow Leopard (10.6.4)
http://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.0.1__final/xcode_3.2.3_and_ios_sdk_4.0.1.dmg Xcode 3.2.3 and iOS SDK 4.0.2 for Snow Leopard (10.6.4)
http://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.0.2__final/xcode_3.2.3_and_ios_sdk_4.0.2.dmg Credits go to Cédric Luthi for telling us the correct url aboveXcode 3.2.4 and iOS SDK 4.1 for Snow Leopard (10.6.4)
http://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.1__final/xcode_3.2.4_and_ios_sdk_4.1.dmg Xcode 3.2.5 and iOS SDK 4.2 GM for Snow Leopard (10.6.4)
https://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.2_gm_seed/xcode_3.2.5_and_ios_sdk_4.2_gm_seed.dmg
But Apple has disabled some of the links recentlyiPhone SDK 2.2.1 Leopard (10.5.4)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_for_iphone_os_2.2.1__9m2621a__final/iphone_sdk_for_iphone_os_2.2.19m2621afinal.dmg iPhone SDK 3.0 (Xcode 3.1.3) Leopard (10.5.7)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.0__final/iphone_sdk_3.0__leopard__9m2736__final.dmg
iPhone SDK 3.0 (Xcode 3.2) Snow Leopard (10.6.0)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.0__final/iphone_sdk_3.0__snow_leopard__final.dmg iPhone SDK 3.1 with Xcode 3.1.4 Leopard (10.5.7)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1__final/iphone_sdk_3.1_with_xcode_3.1_final__leopard__9m2809.dmg iPhone SDK 3.1 with XCode 3.2.1 for Snow Leopard (10.6.0)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1__final/iphone_sdk_3.1_with_xcode_3.2_final__snow_leopard__10a432.dmg iPhone SDK 3.1.2 with XCode 3.1.4 for Leopard (10.5.7)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1.2__final/iphone_sdk_3.1.2_with_xcode_3.1.4__leopard__9m2809.dmg iPhone SDK 3.1.2 with XCode 3.2.1 for Snow Leopard (10.6.0)
http://developer.apple.com/iphone/download.action?path=/iphone/iphone_sdk_3.1.2__final/iphone_sdk_3.1.2_with_xcode_3.2.1__snow_leopard__10m2003.dmg
Update : You are too late, Apple has removed the links above.iPhone SDK 3.1.3 with XCode 3.1.4 for Leopard (10.5.7)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_3.1.3__final/iphone_sdk_3.1.3_with_xcode_3.1.4__leopard__9m2809a.dmg iPhone SDK 3.1.3 with XCode 3.2.1 for Snow Leopard (10.6.0)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_3.1.3__final/iphone_sdk_3.1.3_with_xcode_3.2.1__snow_leopard__10m2003a.dmg iPhone SDK 3.2 Final with Xcode 3.2.2 for Snow Leopard (10.6.0)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_3.2__final/xcode_3.2.2_and_iphone_sdk_3.2_final.dmg Xcode 3.2.3 and iPhone SDK 4 GM seed for Snow Leopard (10.6.2)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_4_gm_seed/xcode_3.2.3_and_iphone_sdk_4_gm_seed.dmg Xcode 3.2.3 and iPhone SDK 4 Final for Snow Leopard (10.6.2)
http://developer.apple.com/ios/download.action?path=/iphone/iphone_sdk_4__final/xcode_3.2.3_and_iphone_sdk_4__final.dmg Xcode 3.2.3 and iOS SDK 4.0.1 for Snow Leopard (10.6.4)
http://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.0.1__final/xcode_3.2.3_and_ios_sdk_4.0.1.dmg Xcode 3.2.3 and iOS SDK 4.0.2 for Snow Leopard (10.6.4)
http://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.0.2__final/xcode_3.2.3_and_ios_sdk_4.0.2.dmg Credits go to Cédric Luthi for telling us the correct url aboveXcode 3.2.4 and iOS SDK 4.1 for Snow Leopard (10.6.4)
http://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.1__final/xcode_3.2.4_and_ios_sdk_4.1.dmg Xcode 3.2.5 and iOS SDK 4.2 GM for Snow Leopard (10.6.4)
https://developer.apple.com/ios/download.action?path=/ios/ios_sdk_4.2_gm_seed/xcode_3.2.5_and_ios_sdk_4.2_gm_seed.dmg
Subscribe to:
Posts (Atom)